写在前面
MTCNN主页: https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
MTCNN论文: https://arxiv.org/abs/1604.02878
MTCNN,采用级联CNN结构,抓住了人脸检测和对齐这两个任务之间内在的相关性。同时做到输出人脸的Bounding Box以及人脸的Landmark(眼睛、鼻子、嘴)的位置。
MTCNN在提出时的凭借着其准确率高速度快取得了很好的结果,至今仍然被广泛的应用于人脸识别的front-end。因此考虑到牛脸检测和对齐于人脸检测和对齐任务的相似性,本文将对使用MTCNN来完成牛脸检测和对齐任务的可行性和方案分析。
MTCNN详解
对于MTCNN的理解需要分为两个阶段MTCNN的推理和训练,MTCNN的推理和训练方式有着非常大的差距,许多人对于这两者之间的概念甚至有着混淆。
网络结构
MTCNN主要通过级联的三个CNN构成(如下图),可以看到随着网络层数的增加,输入图像的尺寸也在逐渐的变大,输出的特征维数也在不断增加,这意味着其利用的信息也越来越多。每个网络虽然类似,但其工作流程还是有着不同和差异。
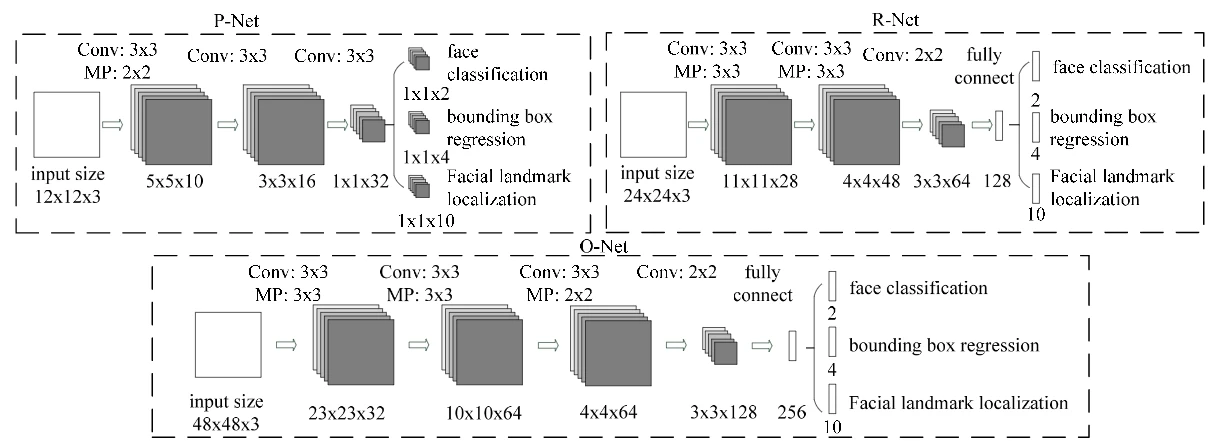
P-net
P-net是一个输入anchor为12x12的全卷积网络(FCN),12x12的区域在经过网络的全卷积之后会变成feature map上的1,根据输入的不同产生的输出也不同,假设输出为$w\times h$则输出的每个点都对应原图像中的一个12x12的区域。工作流程如下图。
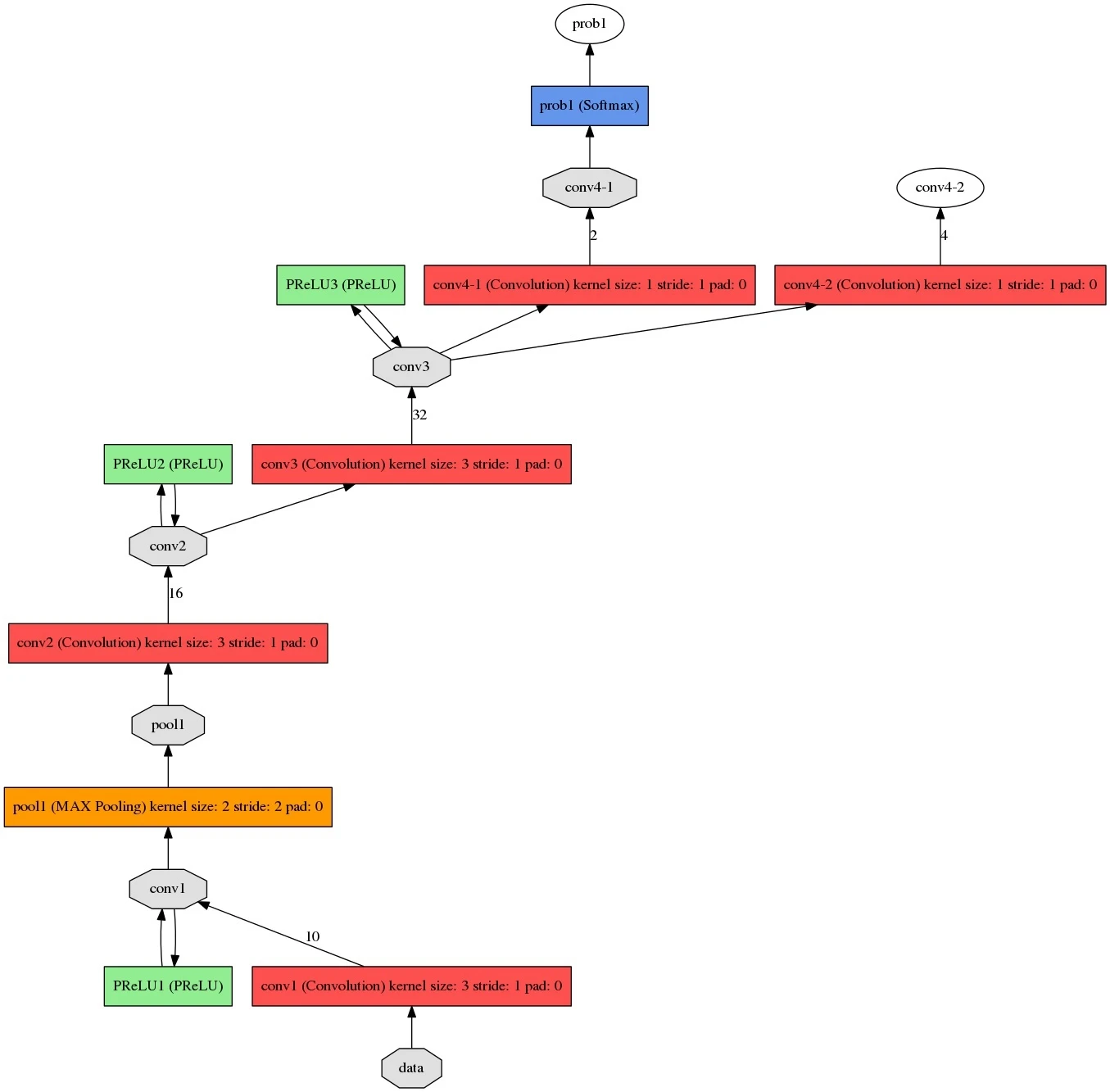
将不同尺寸的金字塔图像输入到P-net中后得到prob1和conv4-2,prob1中包含有bbox的位置信息和置信度,conv4-2中包含bbox的回归系数信息。
利用1中的prob1与conv4-2生成bbox,根据设置的置信度阈值进行筛选,得到一系列的点,映射回原图像后,以此点为左上角,向右向下各扩展12像素,得到12x12的矩形框。
对所有的矩形框进行nms运算。
最后对所有的矩形框根据回归系数进行回归修正,修正过程可以描述为
目标框修正之后,先将目标框按长边调整为正方形,再使用pad将超出原图范围的部分填充为0.
再上述过程中,12x12的anchor可以看作是以stride=1的方式在不同尺寸的图像上滑动
R-net
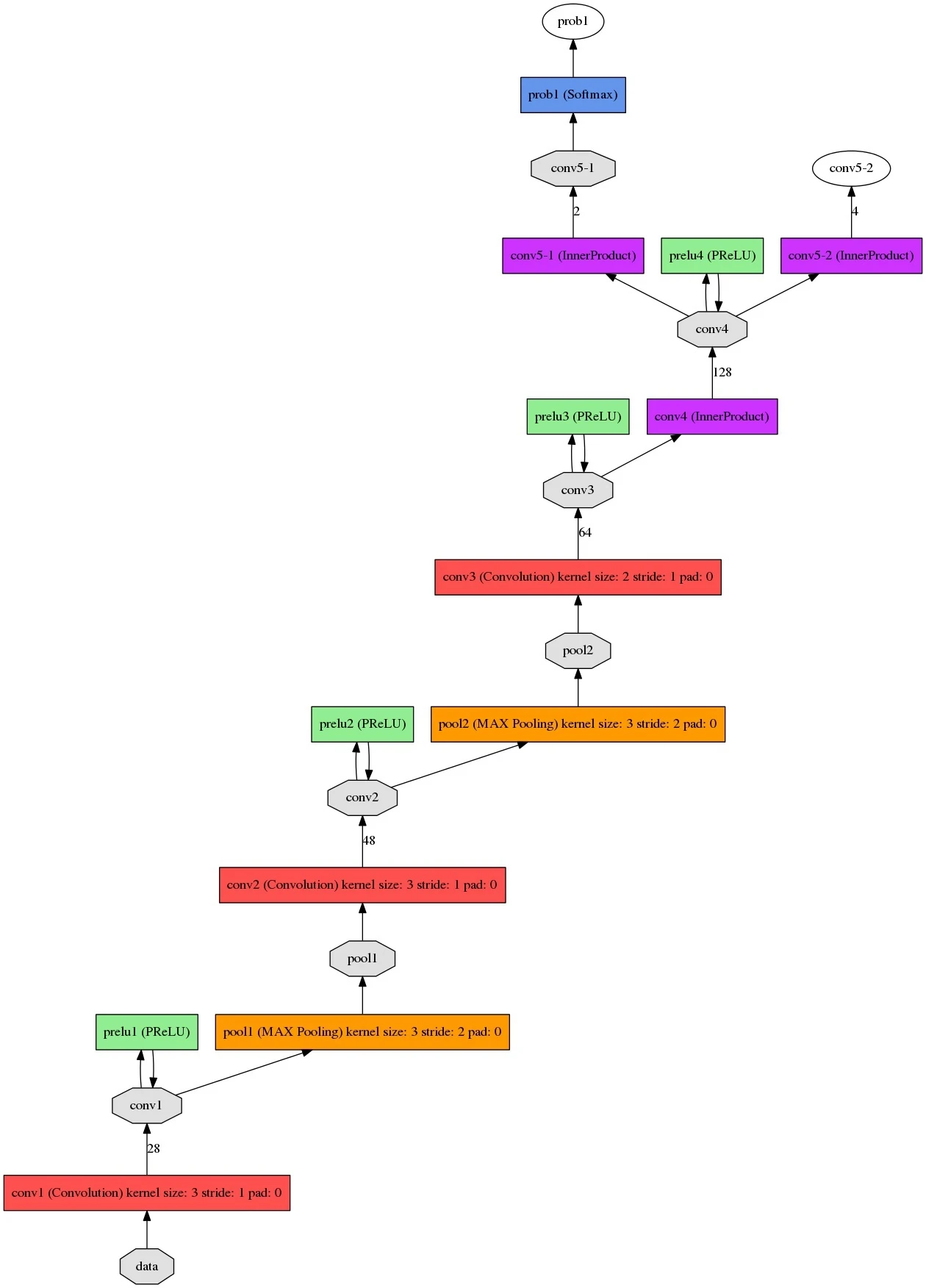
将P-net最后输出的所有bbox,resize到24x24后输入到R-net中。经过R-net后,输出与P-net类似的bbox,同样经过筛选和nms以及调整。
O-net
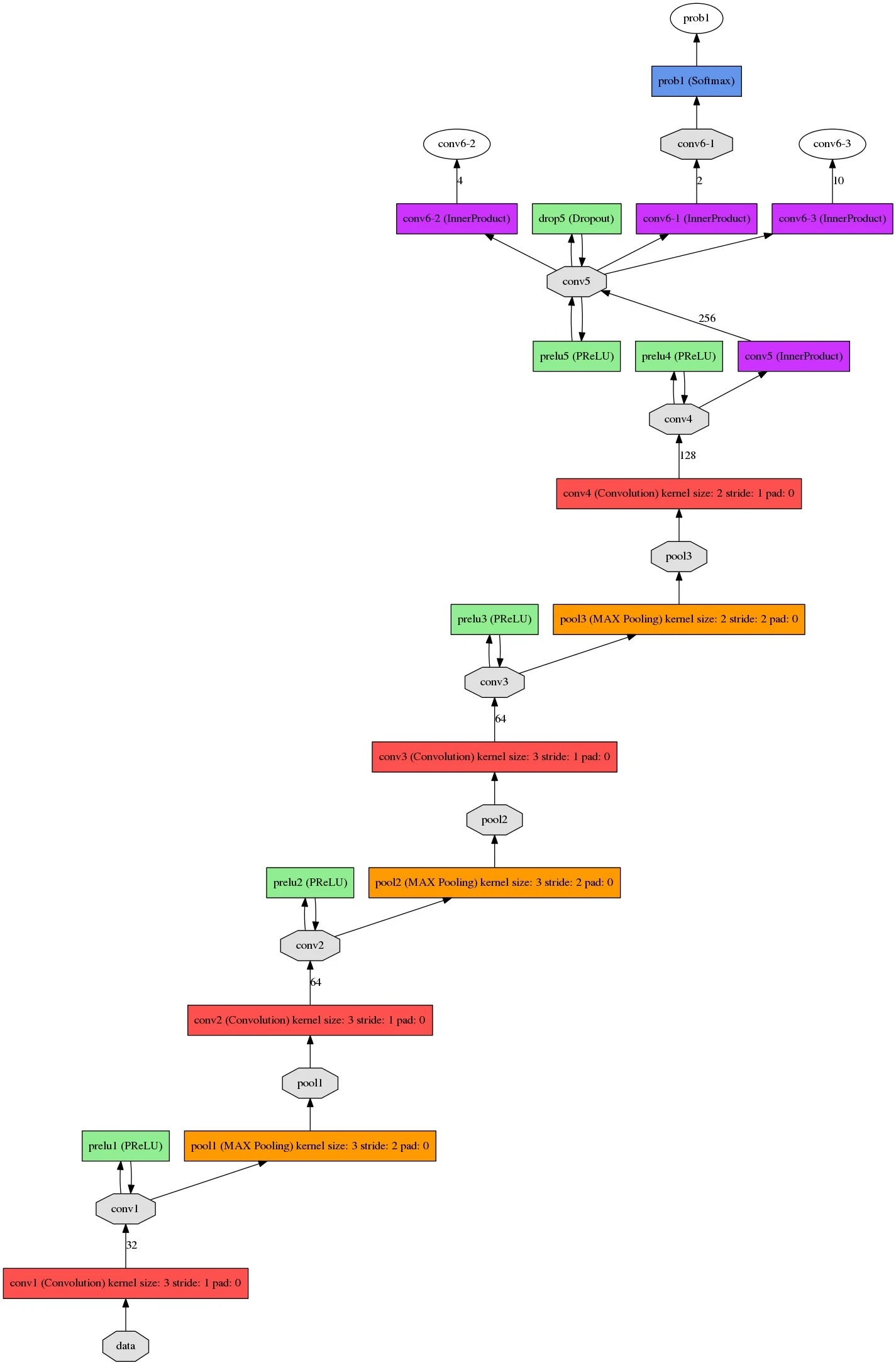
将R-net最后输出的所有bbox都resize到48x48输入到O-net中,输出prob1:bbox坐标信息与置信度、conv6-2的回归系数信息、以及conv6-3的关键点坐标信息。
最后进行筛选和调整,最后进行一次nms输出结果。
推理过程
总体而言,MTCNN的推理过程可以概括为:图像金字塔+三级CNN,在推理过程中的整个流程如下图所示:

第一步: 将test图片不断的Resize,得到图像金字塔。
按照一定的resize_factor来对test图片进行resize,直到大于等于P-net要求的12x12的大小。这样会得到$origin*{resize\_factor},\ orgin*resize\_factor^2 \dots origin*resize\_factor^n$等一系列图片,因为堆叠起来像图像金字塔所以称为图像金字塔。但是需要注意的是,这些图片需要一幅幅的输入到P-net中去,从而得到候选框,然后将候选框反向resize到原图中。
对于resize_factor的选择,一般在0.70~0.80,在原文给出的代码中是0.709,这个参数的选择会影响图像金字塔的层数,层数过多会增加P-net推理过程中的耗时。
第二步: 将图片金字塔输入到P-net,得到大量候选(candidate)。
将根据第一步生成的图片金字塔,逐一的输入到P-net中去,然后得到$n\times m\times 16$的feature map,根据分类得分对所有的$n\times m$个结果进行筛选,然后再根据得到的4个与bbox相关的量,对这些候选根据IOU值进行非极大值抑制后筛选掉一大部分。
NMS的过程可以认为是,每次将队列中最大分数值的bbox左边和的剩下的求IOU,筛选掉IOU大于阈值的框,并把这个最大分数值移动到最后的结果。重复上述操作,以筛选掉大部分overlap的bbox。最后将所有得到的候选根据bbox坐标去原图中截取相应区域的图片后,resize为24x24输入到R-net中去。
第三步: 经过P-net筛选出来的候选图片,经过R-net精炼
根据Pnet输出的坐标,去原图上根据bbox的最大边长正方形去截取出图片,以防止resize形变和保留更多的细节,resize为24x24,输入到R-net中去,R-net会输出二分类的2个输出,bbox的坐标偏移量的4个输出,landmark的10个输出。根据二分类筛选掉不是人脸的候选,对截图的bbox进行偏移量调整后,再次重复IOU NMS进行筛选,后根据bbox坐标去原图中以最大边长正方形截取图像后resize为48x48输入到O-net。
第四步: 经过R-net筛选精炼的图片输入到O-net,输出准确的bbox和landmark
重复类似于R-net的过程,进行IOU NMS筛选,然后选出置信度最高的结果,但这时候需要对landmark也进行偏移量调整,从而获得准确的坐标值,最后得到结果。
训练过程
Loss函数
对于每个网络总体的Loss函数表现为
$$ Loss = min\sum_{i=1}^N\sum_{j\in\{det,box,landmark\}}\alpha_j\beta_i^jL_i^j $$$\alpha_j$ 代表对应任务的重要性,在论文中各个网络的任务重要性设置如下:
P-net: $\alpha*{det} = 1,\ \alpha*{box} = 0.5,\ \alpha\_{landmark} = 0.5$
R-net: $\alpha*{det} = 1,\ \alpha*{box} = 0.5,\ \alpha\_{landmark} = 0.5$
O-net: $\alpha*{det} = 1,\ \alpha*{box} = 0.5,\ \alpha\_{landmark} = 1$
$\beta*j\in\{0,1\}$代表样本的类型,如若$\beta*{det}=1$则代表此图像参与到检测的训练。
而对于每个训练任务有着不同的损失函数$L_i^j$
det: 使用交叉熵的形式来构造损失函数
$$ L_i^{det} =-(y_i^{det}\log(p_i) + (1-y_i^{det})(1-log(p_i))) $$其中$p_i$是网络产生的置信度,而$y_i^{det}\in\{0,1\}$代表的是标注的的确值。
box
使用欧几里得距离来构造损失函数
$$ L_i^{box} =|| {\hat{y}}_i^{box} - y_i^{box} ||_2^2 $$其中$\hat{y}\_i^{box}$是网络中获取的回归结果,而$y_i^{box}\in\mathbb{R}^4$是标注的的确值坐标,
landmark
使用欧几里得距离来构造损失函数
$$ L_i^{landmark} = ||{\hat{y}}_i^{landmark} - y_i^{landmark}||_2^2 $$其中$\hat{y}\_i^{landmark}$是网络中得到的坐标,而$y_i^{landmark}\in\mathbb{R}^{10}$是标注的的确坐标。
在线样本挖掘
仅在训练face/non-face classification时使用,具体做法是:对每个mini-batch的数据先通过前向传播,挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失。
数据预处理
检测与BBox任务:根据IOU的计算方式,从标注的图像中截取出一定大小的图像,使得截取的图像区域与标注的区域的IOU计算值满足指定的条件。
Landmark任务:获取标记了5个关键点的人脸图像。
训练时模型输入
训练时,在不修改网络卷积与池化参数的前提下,在合乎论文原意的基础上,训练输入图片的大小都需要按照论文中给出大小进行。也就是说如果需要使用非12x12的图像进行训练则会对损失函数的计算和反向传播的流程进行调整,或者修改网络卷积和池化的结构。
用于牛脸
可行性
从可行性上来说,人脸和牛脸具有结构意义上的相似性,这意味着适用于人脸的模型,在一定程度上也能适用于牛脸。但是牛脸的特征相较于人脸有着不同,虽然MTCNN使用卷积的方式提取特征,那么对于卷积核的选取可能需要进行调整。、
调整
首先考虑到,现有数据集分辨率较高,而网络结构中的感受野普遍较小,所以可以考虑在进行训练时,缩小现有数据集图像的分辨率,以适应网络较小的感受野。
考虑到牛脸的大小普遍的大于人脸,以及对于有限数据集的充分利用。可能需要对网络的anchor进行大小的调整,以接受更大的视野和获取更多信息来满足需求,但对于需要调整至多少大小能较好的平衡性能和准确率,仍然需要实验进行验证。
其次是对于各种参数,乃至网络结构的微调以满足牛脸识别的需要。这些调整也需要纳入到考虑当中。