DeepSeek for Research?
Abstract
Recently released weight open model deepseek-v3 and deepseek-r1 have brought a new wave of AI fever. Impressive user experience of deepseek-r1 has once again sparked the AI craze. In this report, we will introduce the characteristics of deepseek-r1, the details of the principles behind it, and its innovative points and differences from existing LLM models. After that, this report will further explore how deepseek-r1 can help academic research, introduce the role of prompt engineering in deepseek-r1, existing tools and solutions, and the problems faced by LLM in assisting academic research.
在2025年春节期间发布的权重公开模型 deepseek-v3 和 deepseek-r1, 其中的深度思考模式,即 deepseek-r1,惊人的使用体验,再一次的引发了所谓的 AI 热潮。 本次汇报将介绍 deepseek-r1 的特点,其背后的原理细节以及其创新点与现有 LLM 模型的区别。 在此基础上,本次汇报将进一步探索 deepseek-r1 如何助力学术研究,介绍提示词工程在 deepseek-r1 上的作用, 现有的工具和解决方案,以及LLM在辅助学术研究中所面临的问题。
DeepSeek-R1
推理模型
在介绍 DeepSeek-R1 之前需要先介绍下LLM的构建步骤。下图展示了 LLM 构建阶段。
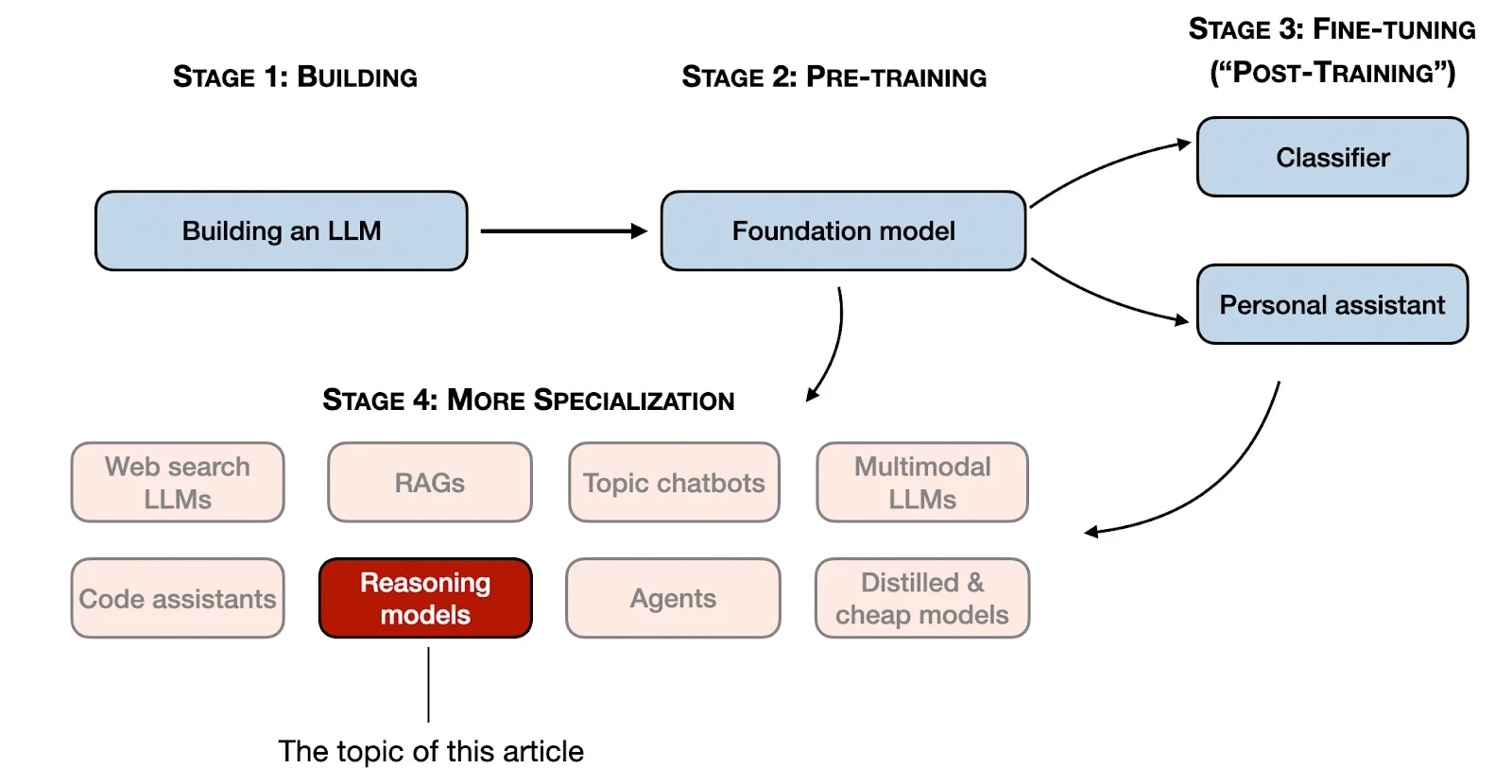
其中阶段1-3是开发LLM的常见步骤,包括后续的微调。但是随着LLM的发展,阶段4展示了对于LLM的更多特化方向。而其中的推理模型正是几天我们介绍的 DeepSeek-R1 模型的特化形式。
DeepSeek-R1 是在预训练模型 DeepSeek-V3 基础上特化训练而来的推理模型。所谓推理,可以理解为「回答需要复杂,多步生成并包含中间步骤问题的过程」。
举个例子,虽然现在大多数LLM都具备基本的「推理能力」,能够回答诸如「如果一列火车以每小时60英里的速度行驶3小时,它会行驶多远?」这样的问题。但是对于普通的LLM可能只会提供一个简短的答案,而推理模型通常会包含中间步骤,从而揭示部分思考过程。(需要注意的是,许多未专门针对推理任务开发的大型语言模型也可以在其答案中提供中间推理步骤。)如下图所示。
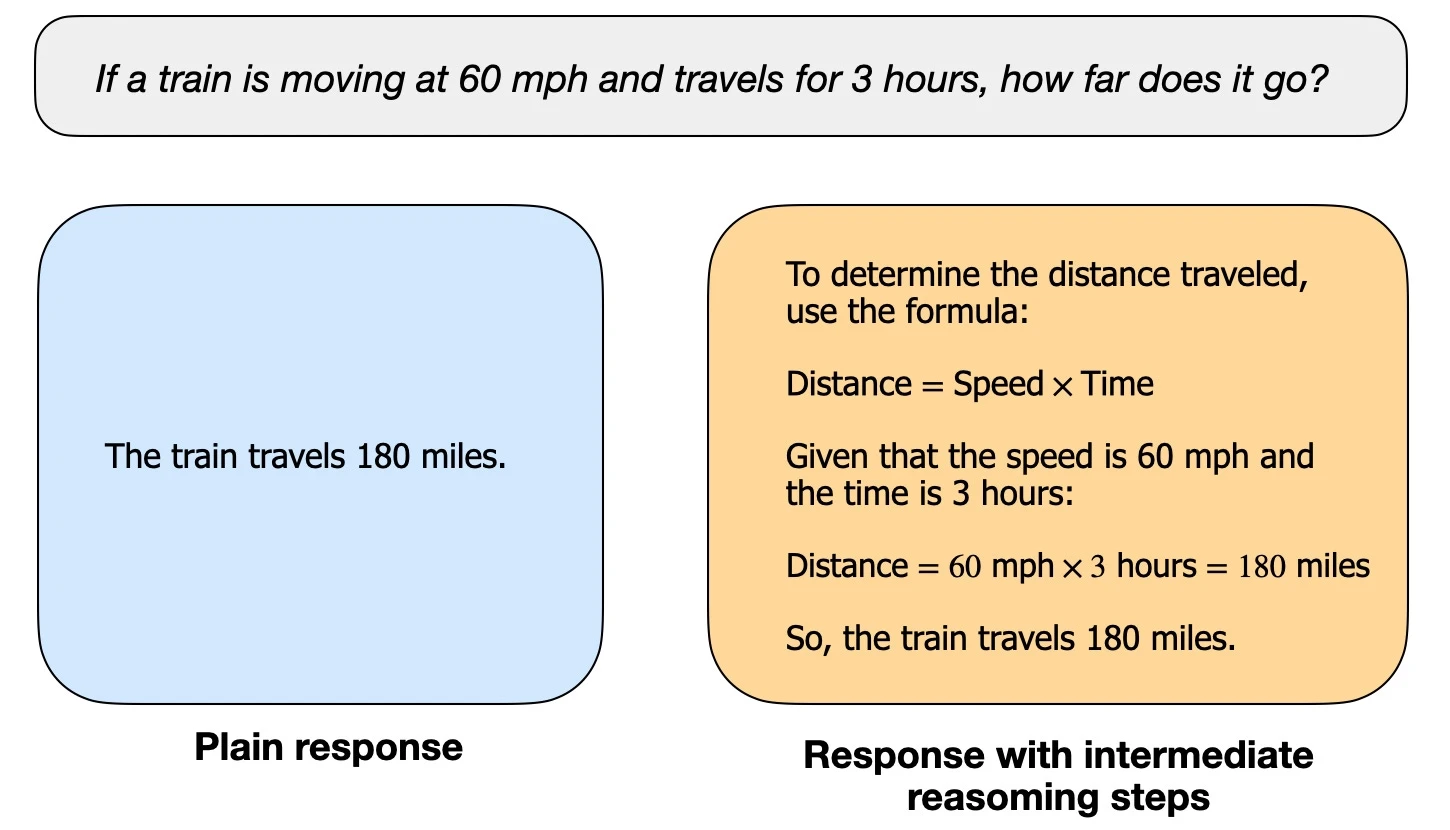
不同的模型对于中间推理过程的展示也不尽相同,例如 OpenAI的 o1 模型不会展示其推理过程,而 DeepSeek-R1 则会向用户展示其推理过程。
推理模型更加擅长解决复杂任务,例如解谜、高级数学问题和具有挑战性的编程任务。然而,对于更简单的任务(如摘要、翻译或基于知识的问答),它们并不是必需的。事实上,对所有任务都使用推理模型可能会效率低下且成本高昂。例如,推理模型通常使用成本更高、响应更冗长,有时由于“过度思考”而更容易出错。这里同样适用一个简单的原则:为任务选择合适的工具(或类型的LLM)。
训练流程
DeepSeek-R1 其中另一个最显著的特点是其训练流程中只使用了RL(强化学习)而不是 RLHF 来训练。需要注意的是,DeepSeek实际上发布了三种变体的 R1 模型,包括:DeepSeek-R1-Zero、DeepSeek-R1和DeepSeek-R1-Distill。
下图为其技术报告中给出的训练流程:
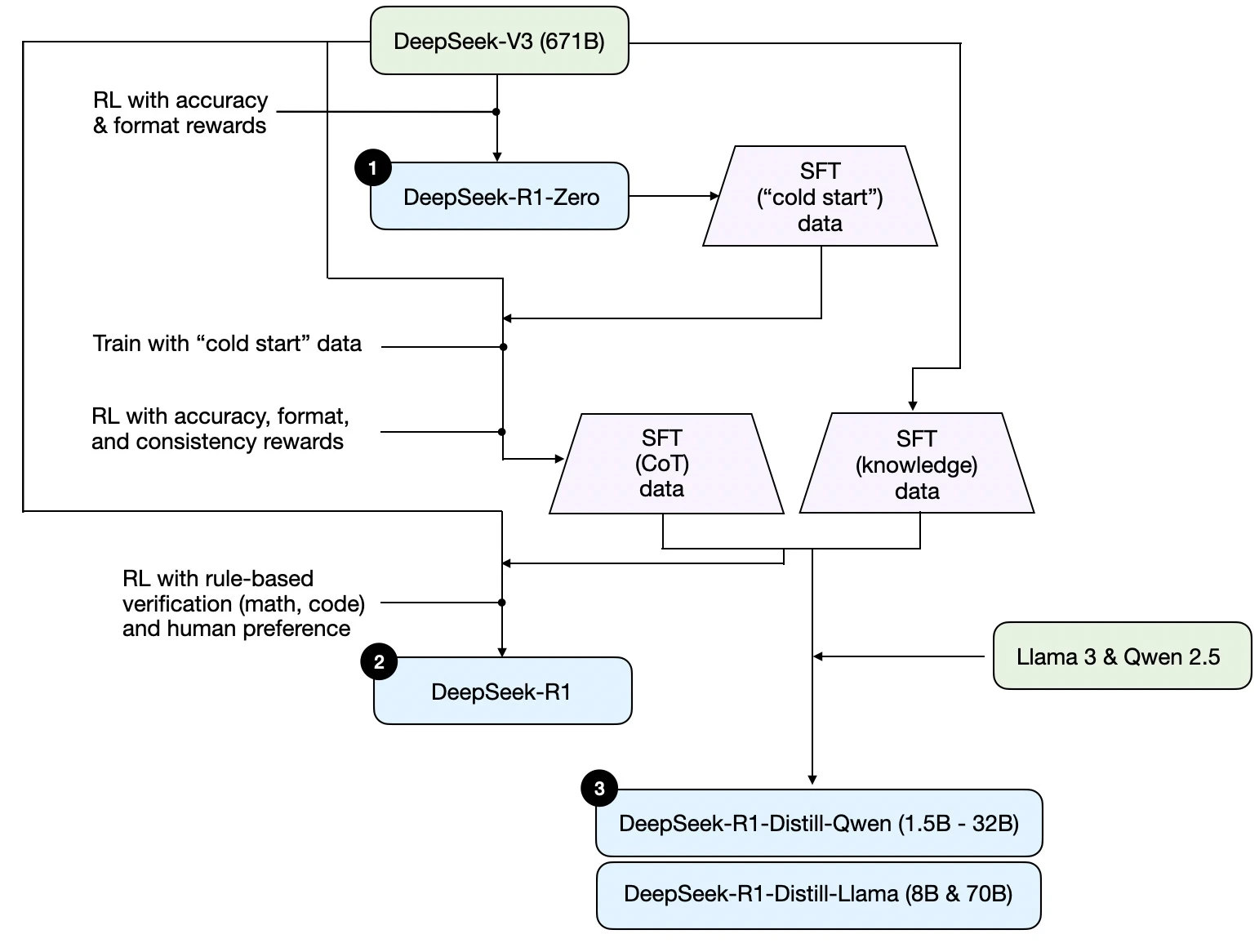
其中 DeepSeek-R1-Zero 基于 DeepSeek-V3 基础模型训练而来,研究团队使用两种奖励函数进行强化训练,这种方法称为冷启动训练,因为其并没有使用监督微调(Supervised Fine-Tuning)和 RLHF(Reinforcement Learning with Human Feedback)。
在 DeepSeek-R1-Zero 的基础上,研究人员收集了其产生的 cold start 数据和 CoT 数据,并从 Base 模型中收集了数据进行人工标注后作为训练 R1 的冷启动数据,并在 DeepSeek-V3 的基础上再次训练得到 DeepSeek-R1。
对于 DeepSeek-R1-Distill 的训练,研究人员从DeepSeek-R1中蒸馏得到数据并在 Llama3 和 Qwen 2.5 上使用 SFT 获得蒸馏模型。
强化训练
对于强化训练,DeepSeek 研究团队使用了冷启动的方法进行训练,并应用了两个奖励函数:
准确率奖励:准确率奖励评估模型输出的结果是不是正确的,例如对于编程问题,使用编译器给出的反馈来判断准确率。
格式奖励:对于格式奖励其主要判断模型是否按照开发人员设定的格式模式输出。
另外在其他的强化学习阶段,研究人员也引入了语言一致性奖励等提升稳定性和人类表现分奖励模型来提升模型的人类可读性。
Group Relative Policy Optimization
传统强化学习(如PPO)依赖独立的价值模型(Critic)评估状态价值,而GRPO通过组内相对优势估计替代价值模型。具体来说,对每个问题采样一组输出,基于组内奖励的均值和标准差计算优势值 $(A_i = \frac{r_i - mean(r)}{std(r)})$,省去了训练价值模型的开销。具象化可以理解如下。
对于对于每个问题输入,模型对对于此输入生成多个结果,这些结果称为一个组,对于这样一个组对其进行组内的奖励函数的计算, 然后在计算得出的一组得分进行标准差计算,得到该组内的最佳结果,从而据此给给模型反馈进行学习。
这样的策略使得模型不需要依赖价值模型给出的打分结果,从而减少了训练时的计算开销。
架构创新
相较于原始的 Transformer 架构,DeepSeek 替换了其中的 Attention 和 Feed-Forward,从而实现了训练成本的降低。
DeepSeek MLA
DeepSeek 使用 DeepSeek MLA 替换了架构原始的 Attention。在原始的 Attention 中,在对 Token 进行计算时,需要同时对所有的输入 Token 进行计算和查询,而原始的的 Token 的向量维度庞大,DeepSeek 对词向量使用线性降维,再在后续升维来降低 Attention 的计算性能需求。
此外为了进一步降低计算的性能消耗,DeepSeek MLA,将 Key 和 Value 混合降维到同一个 Latent Space,来进一步优化显存消耗。同时为了弥补降维带来的信息损失,DeepSeek MLA 引入位置掩码来补全 Token 的原始信息。
DeepSeek MoE
Dynamic Router
DeepSeek MoE采用动态专家选择机制,通过可学习的路由网络对输入特征进行实时分析。具体而言,每个token会通过门控函数g(x)=softmax(Wg⋅x)g(x)=softmax(Wg⋅x)计算出对各个专家的选择权重,其中WgWg为可学习参数。与静态路由不同,DeepSeek动态路由引入 局部敏感哈希(LSH) 机制,对相似语义的输入自动聚类,显著提升专家选择的语义一致性。实验表明,该机制使专家利用率从传统MoE的58%提升至83%。
Load Balance on Train
针对MoE训练中常见的专家负载不均衡问题,DeepSeek提出双阶段正则化策略:
- 批量级均衡:通过KL散度约束每个batch内各专家的处理token数分布
- 全局级均衡:采用移动平均记录长期负载分布,通过余弦相似度损失进行调节
该方案在32专家配置下,将负载方差从±18%降低到±6%,同时保持模型容量利用率达91%。
Next Token Prediction
DeepSeek-R1在传统自回归预测基础上引入因果稀疏注意力机制,通过以下创新提升预测效率:
- 层次化窗口注意力:将64k上下文窗口划分为256个区块,每个区块内进行局部注意力计算,同时通过跨区块的top-k相似度选择建立全局连接
- 预测置信度校准:使用温度缩放(Temperature Scaling)和直方图分箱(Histogram Binning)对输出logits进行校准,使预测置信度与真实准确率的ECE误差从0.15降至0.07
- 动态词汇扩展:针对学术文献中的专业术语,实时检测OOV(Out-of-Vocabulary)词汇并触发子词动态组合机制,使生物医学文献的未登录词识别率提升37%
For Research
提示词工程
对于 DeepSeek-R1,其技术报告指出,简短的提示词反而能取得更好的效果。如下图所示,更短的提示词能获得更好的效果。

对于非推理型模型,一般提示词的编写遵循分为两种范式:单轮对话与多轮对话。
对于单轮对话的提示词,一般以说清楚需求为主要目标,如对于提出文档总结的提示词,只需要指出「请帮我总结上述/下面的文档」即可。而对于多轮对话的提示词,参考推理模型的推理过程,一般以前一轮对话能为后一轮对话提供有效信息的范式进行编写。
如果实在不知道如何编写提示词,可以使用更高性能或者提示词生成特化的模型生成提示词。
论文阅读与总结
现有的基于 pdf 和文档的论文阅读和总结主要分为下面几种实现方案:
- 对文档中的文字进行提取,并进行向量嵌入,使用 RAG 来实现论文阅读。小上下文窗口模型的实现方式
- 对文档中的文字进行提取,然后直接作为上下文实现论文阅读。大上下文窗口模型的实现方式。
- 直接输入文档进行多模态的理解与文本生成。对于多模态模型可以采用的方式。
对于第一种方案,其所采用的向量嵌入模型和 RAG 的算法会显著影响最终的性能。
对于第二第三种方法则更加考验模型的性能。
就论文的总结和阅读来说,一般使用官方提供的 webui 即可,但是对于目前的 DeepSeek 官网算力不足的现状,可能更好的是使用基于 API 的自有 webui 或者客户端。同时对于官方算力不足的现状,也可以使用第三方算力服务平台,比如硅基流动。
科研知识体系搭建
对于科研知识体现的搭建目前有两种方式,一种是对模型进行专业化微调从而获得对于私有科研知识的理解,另一种则是基于 RAG 搭建数据库从而辅助 LLM 在回答问题时的表现。
对于前者目前并没有一个易用的方案来来使用,但对于后者,目前已经有比较多成熟的应用可以使用了。比如 RAGFLow可以用工作流的方式定义RAG的算法、比如 CherrySudio 允许本地搭建小型知识库。
方向调研
在方向调研方面,目前并没有一个较为成熟的 LLM 应用出现,现有的 LLM 应用虽然能进行联网检索,但其并不能准确的检索到学术论文信息。目前现有的基于AI的调研工具,例如 GPT Research(付费测试)、星火科研助手(效果不佳),GPT-Researcher(开源但无法进行学术研究),均难以满足日常的调研所需。
LLM 科研应用目前的问题
虽然 DeepSeek-R1 的在计算等逻辑相关任务上展现出了强大的性能表现,但其仍然无法摆脱模型幻觉,甚至由于其过度思考在某些情况下反而更加的严重。其技术报告也指出了,R1 模型的指令遵循性能反而下降。
此外现有的 LLM 模型均为权重固定的模型,而科研界的信息则是在不断迭代。LLM 对于领域特定知识形成的经验会很快的过时,从而使得微调来构建科研大模型存在工程上的挑战。而使用 RAG 方法对模型能力进行扩展,一方面受限于模型本身的性能,一方面还受限于 RAG 算法的性能,此外现今并无一个统一接口的学术信息数据库,使得自动化检索学术信息的实现成本很高,这也不利于相关场景解决方案的发展。